
Civis Platform provides a Data Catalog to help you and your team discover, organize, and collaborate around datasets.
Imagine you are faced with a typical task: as a data analyst, you are tasked with building a quick report on your website’s weekly visits. All the data are available in your Civis Platform database. There are more than 50 schemas and hundreds of tables. Where to start?
- Civis Platform’s Data Catalog lets you browse, search and filter schemas and tables in the Data Pane, so that you can quickly look for tables that have “website_analytics” in their names and are tagged with “reporting” by your teammates.
- Once you find the correct table, you can explore its data before building the report. Civis Platform’s Data Catalog provides Table Snapshots and Table Details for you to quickly gain an understanding of the table.
- You can run SQL queries in the Query tool for further exploration. You can have the Table Snapshot open next to Query so that you can write your SQL queries while being able to reference column data types in the same view.
The steps above highlight just a few ways you can leverage Data Catalog. Continue reading to learn more about each of these features.
How to access the Data Catalog?
You can access the Data Catalog by clicking on the database icon in the navigation pane on the left. From there, you can access the Data Pane where you can view all the schemas and tables that are available to you, search schemas and tables, view a table’s Table Snapshot and Table Details, and organize tables with Tags.
Data Catalog Features
Data Pane
The Data Pane is Platform’s UI display into your database (Redshift or Postgres), where Civis stores all your structured data. You can view all the schemas and tables that are available to you, expand schemas to see table names, expand tables to see column names, and from there click on table names to view Table Snapshot and Table Details.
You can navigate to the Data Pane by clicking on the navigation pane’s database icon on the left (highlighted in red in the screenshot below).
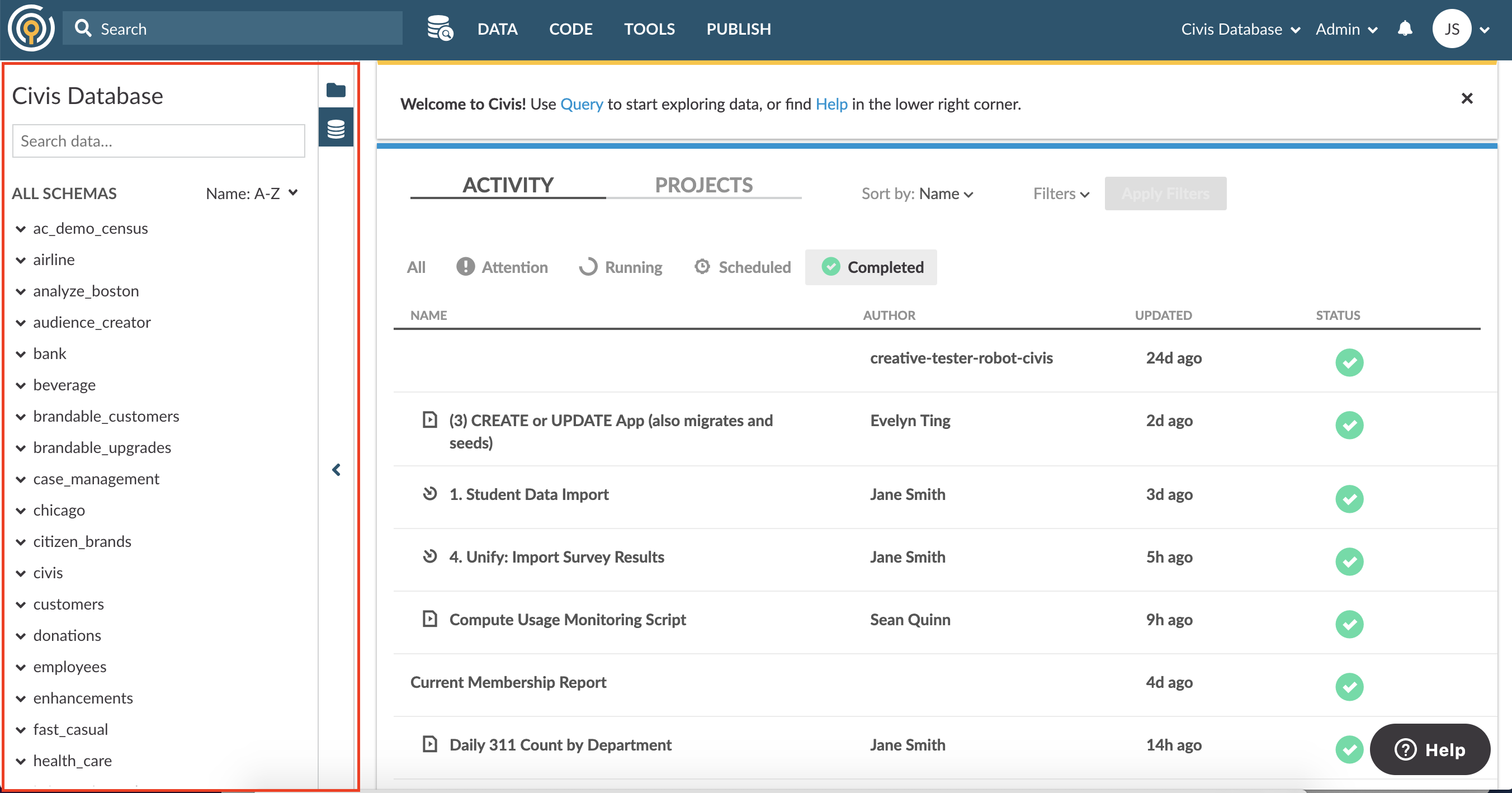
Please note that the Data Pane is not a live look at the cluster's structure. Platform detects updates to the structure (new tables and updated tables) and then scans those changes so that Platform can display them. You can click on Update Available Data to initiate an update. For more details on how Platform Updates Data Catalog, please here.
To access or interact with tables in real-time without leaving Platform, you can use Platform‘s Query to write SQL queries against your Redshift database and see the output displayed without the need for an external SQL client. For more details on Query, please go here.
Schema / Table Search
In the Data Pane, you can search for specific schemas and tables by inputting search keywords in the search bar. The search results are schemas and tables that contain the search keywords in their names. Your search keyword must have 3 or more characters.
You can also search tables by their associating Tags. To do so, click on the Tags filter under the search bar.
Here’s an example of how you can search for tables with keywords and tags. Suppose your organization has created an airline schema and tagged some tables for Reporting purposes. To look for tables under the airline schema that are meant for Reporting, you can type “airline” in the search bar and select Reporting from The tags filter.
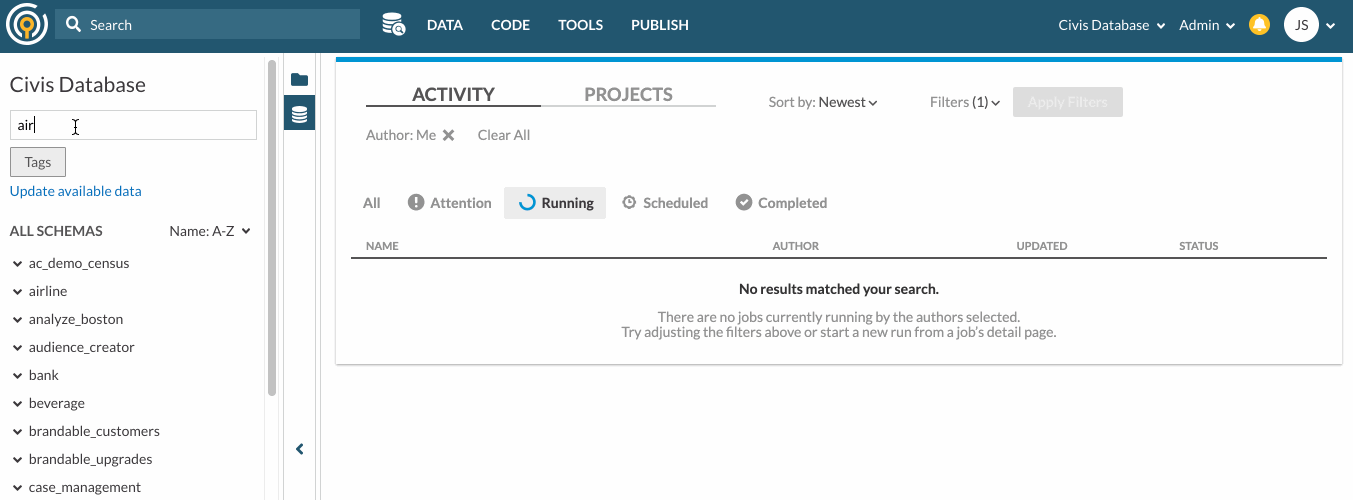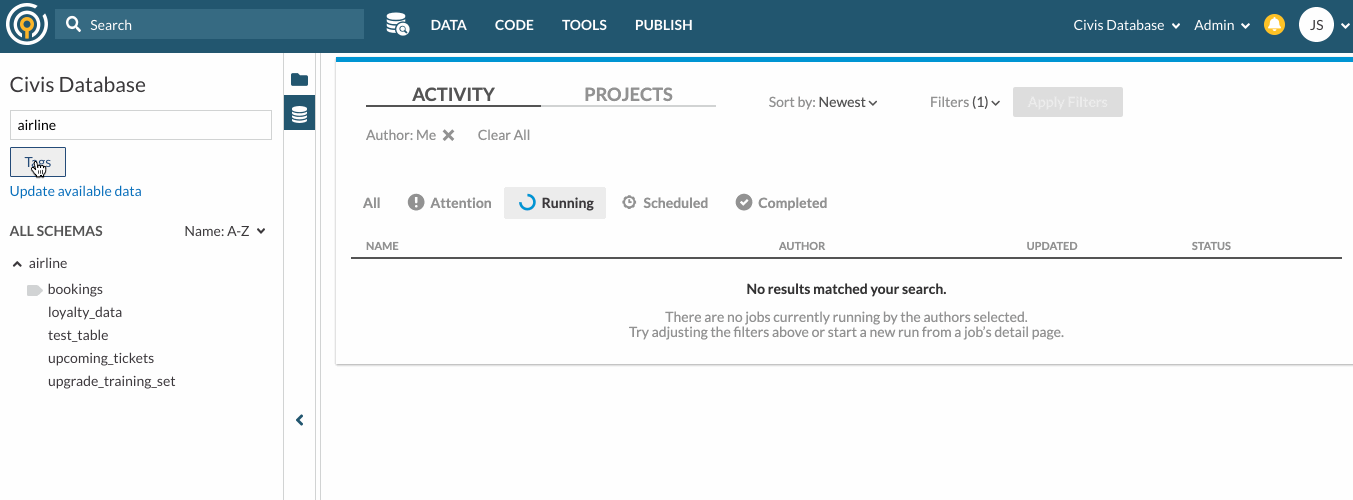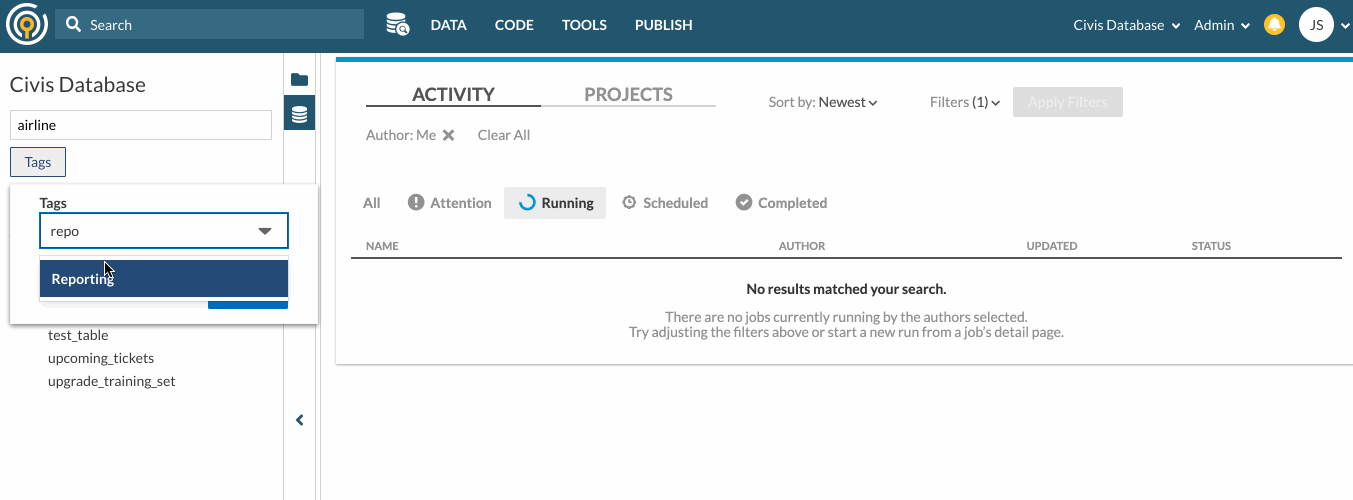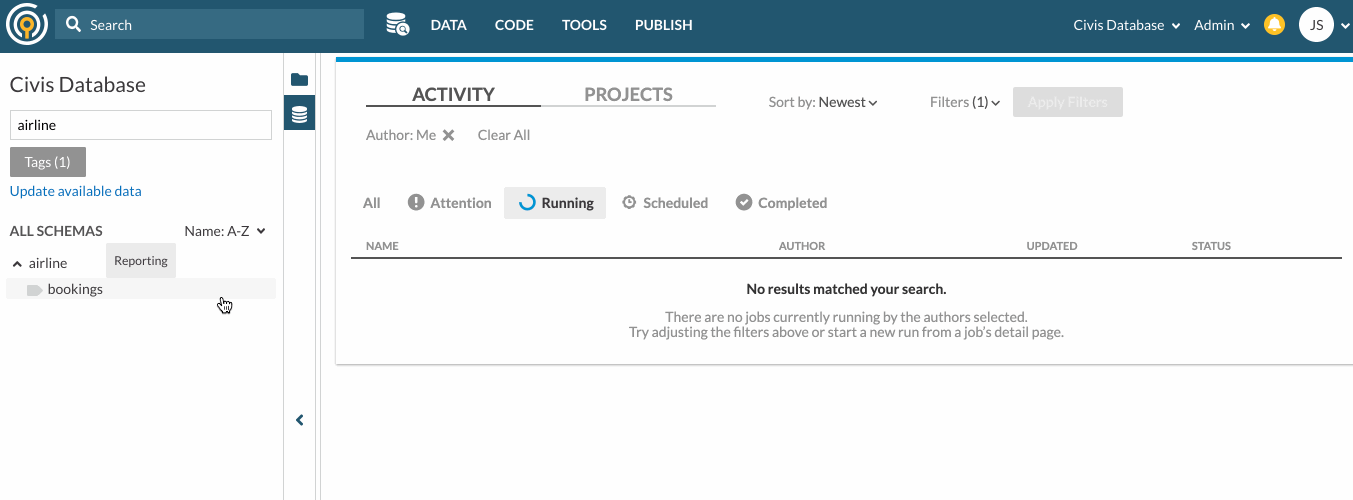
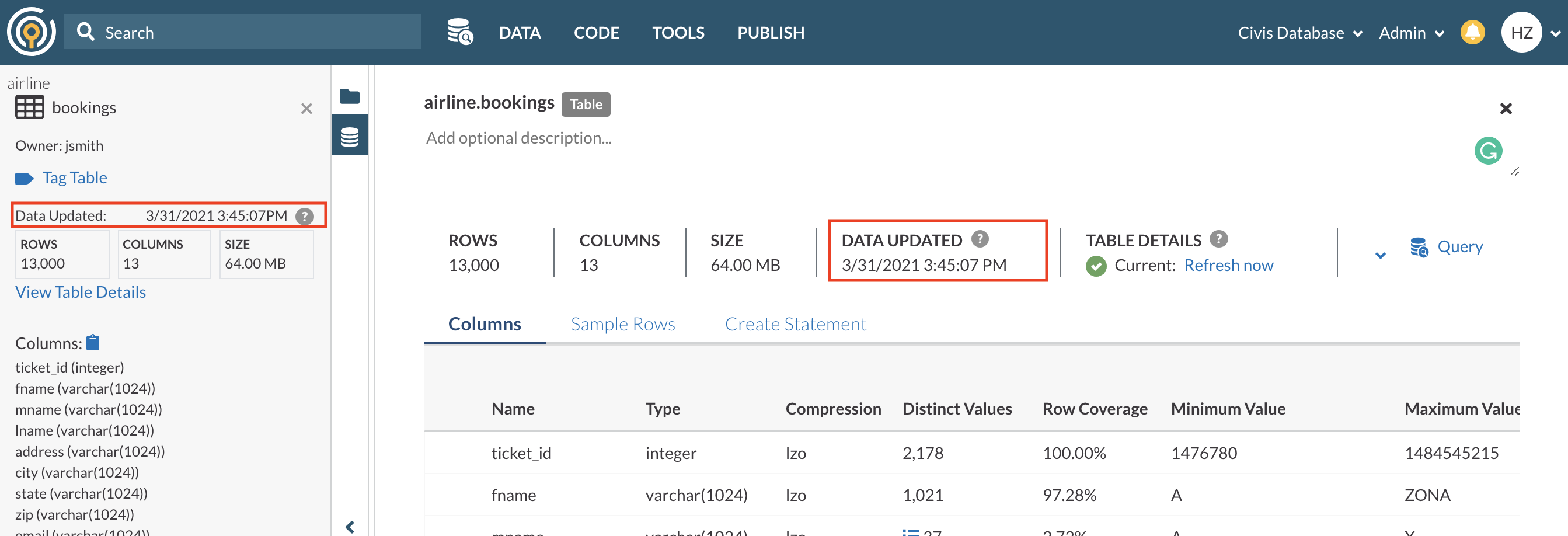
Table Snapshot
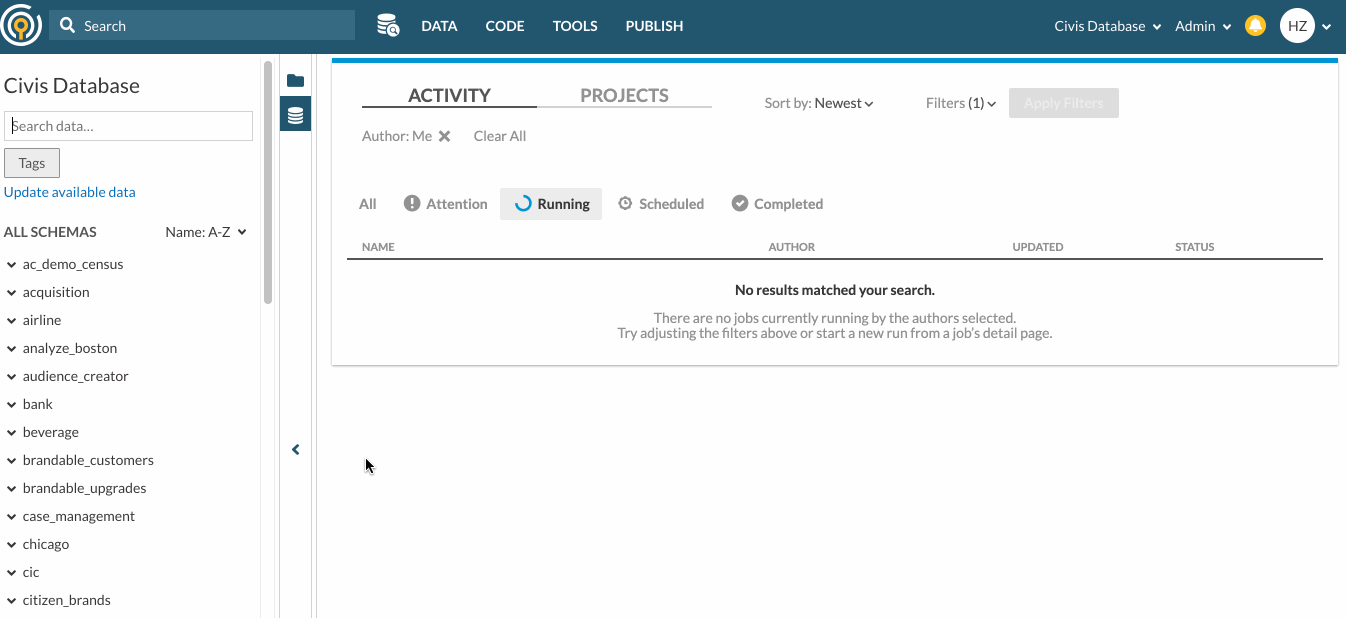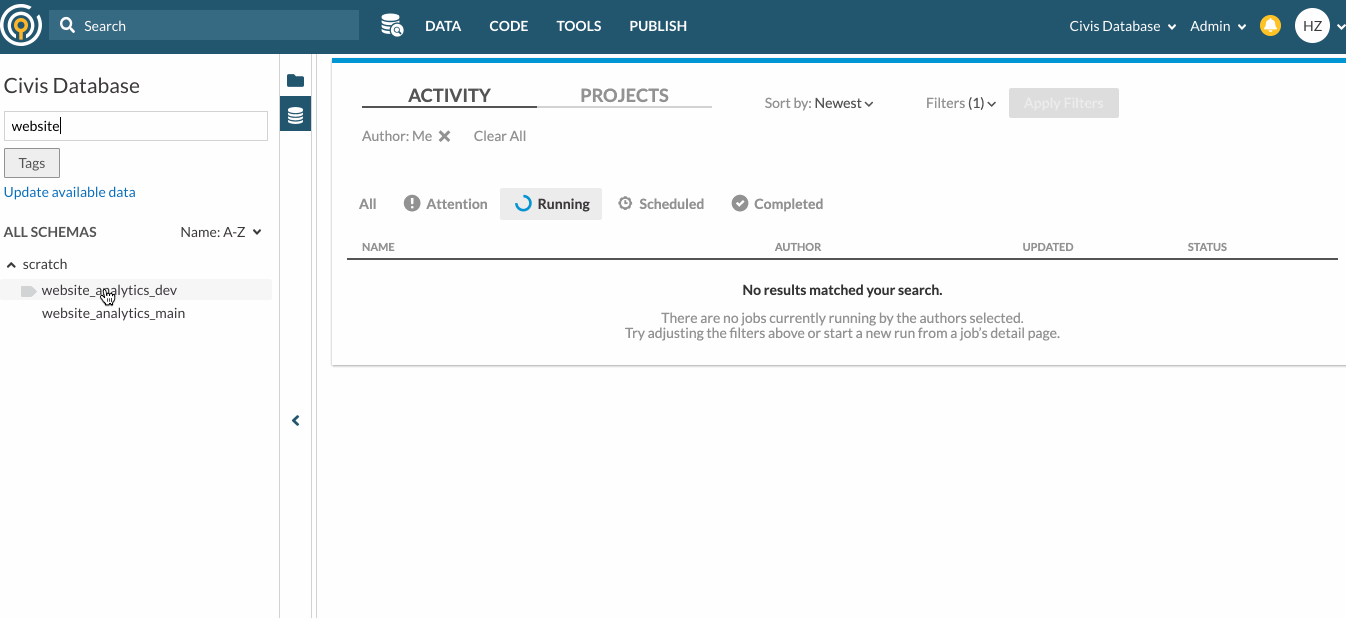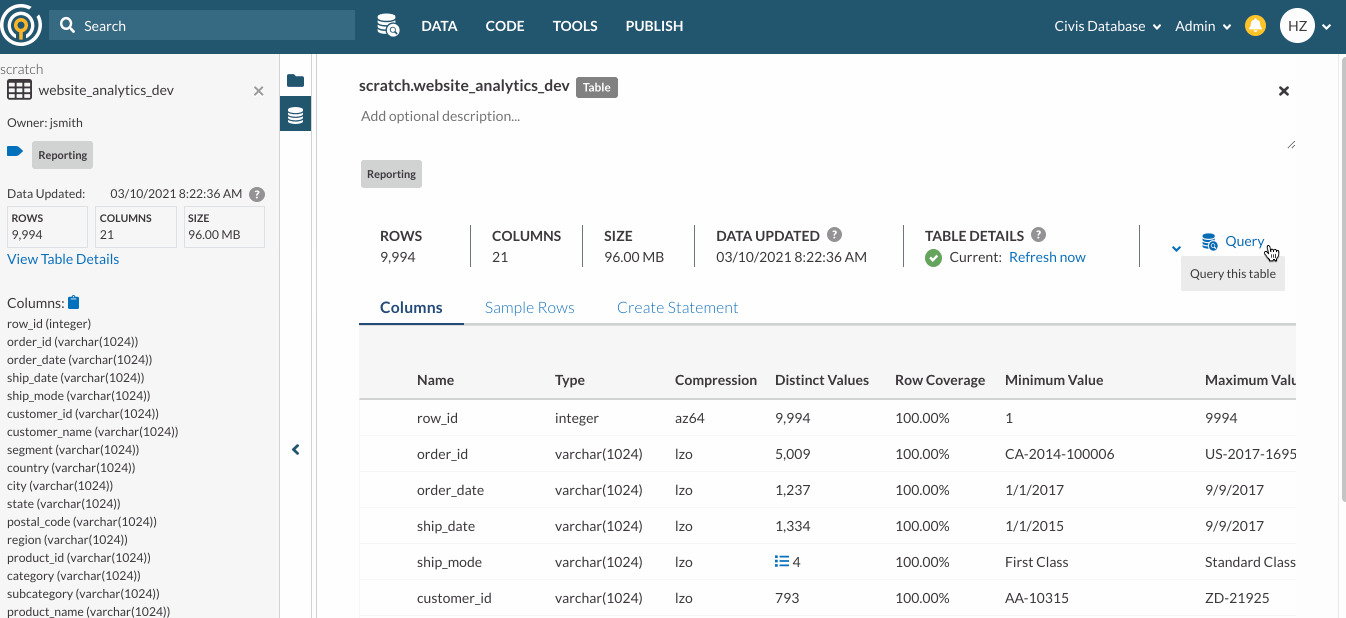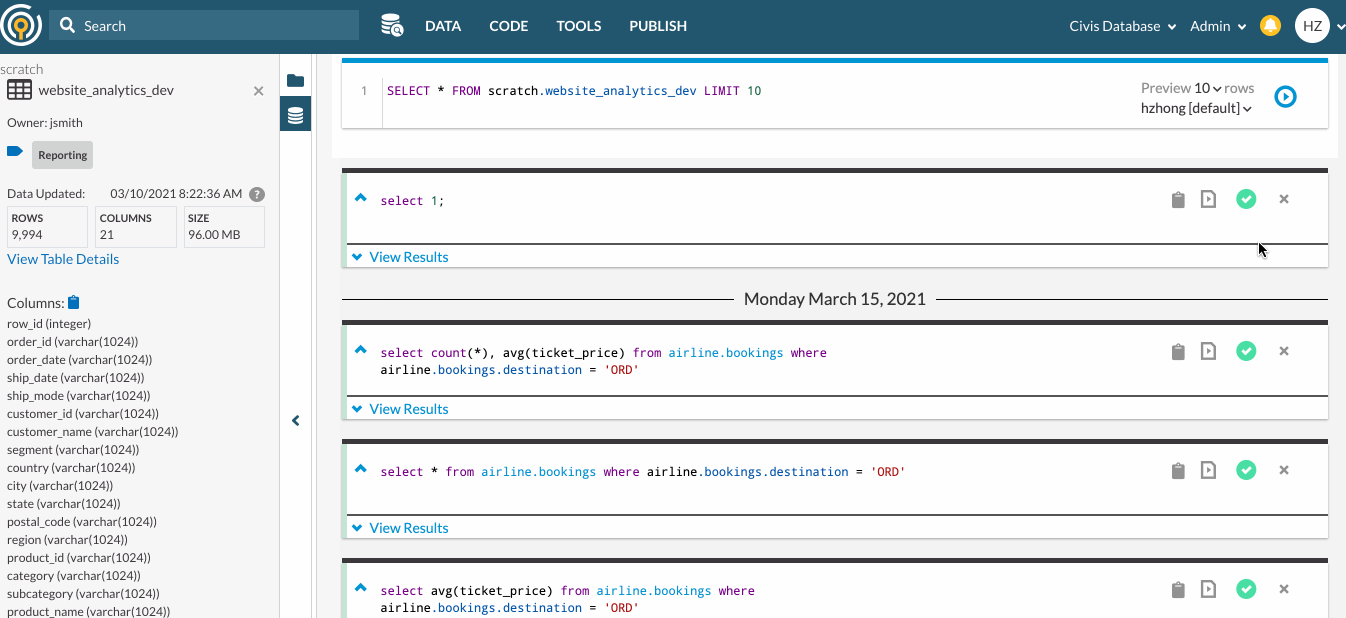
From the Data Pane, you can click on table names to view their Table Snapshot (highlighted in red in the screenshot below).
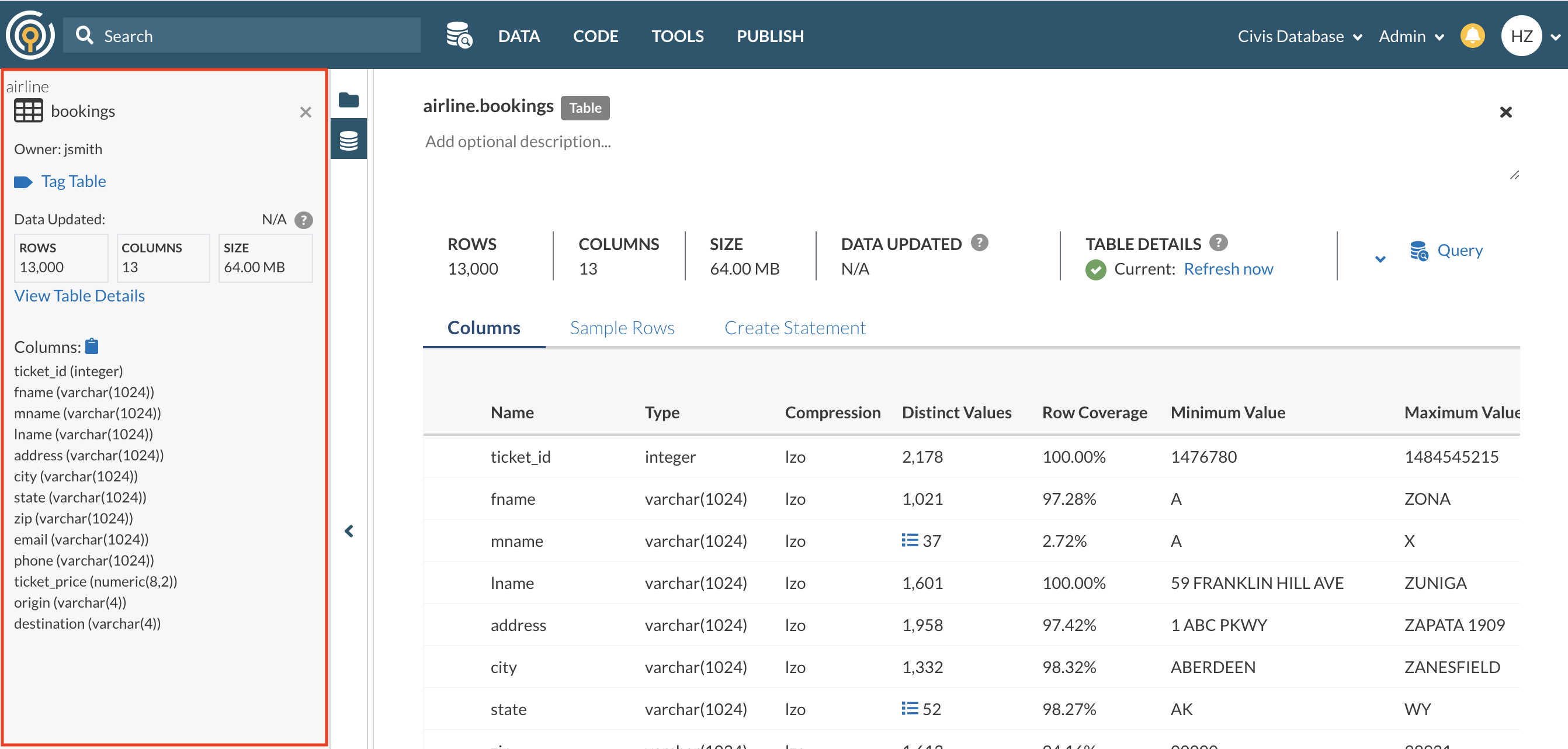
A table’s snapshot provides you with information to get a quick understanding of the table. This information includes
- Description - anyone who can see the table can add a table description in Table Details. Table Snapshot will display the description if available.
- Owner
- Any Tags the table is associated with for quick context.
- Data Updated timestamp - the most recent time Platform has detected changes to the data or schema. For more details, please go here.
- Number of Rows
- Number of Columns
- Table Size
- A list of Table Columns and their data type
You can click on the clipboard to copy all the columns, enabling you to quickly get all the columns in a comma-delimited format easily consumable in a SQL query.
Important: Please note that Table Snapshot is not a live look at the table.
- If you have changed a table's structure, but Platform has yet to reflect those changes, you can click Update Table Details in the Data Pane. This updates table names, column names, and column data types. For newly created tables, the table will appear in the data pane after running this job.
- You can also click on Refresh Now in the Table Details if you want to update information about the table’s data, such as the row count, sample raw rows, and column statistics- min, max, etc.
- For more details on how Platform Updates Data Catalog, please go here.
Table Details
From the Table Snapshot, you can click on View Table Details to view the table’s Table Details (highlighted in red in the screenshot below).
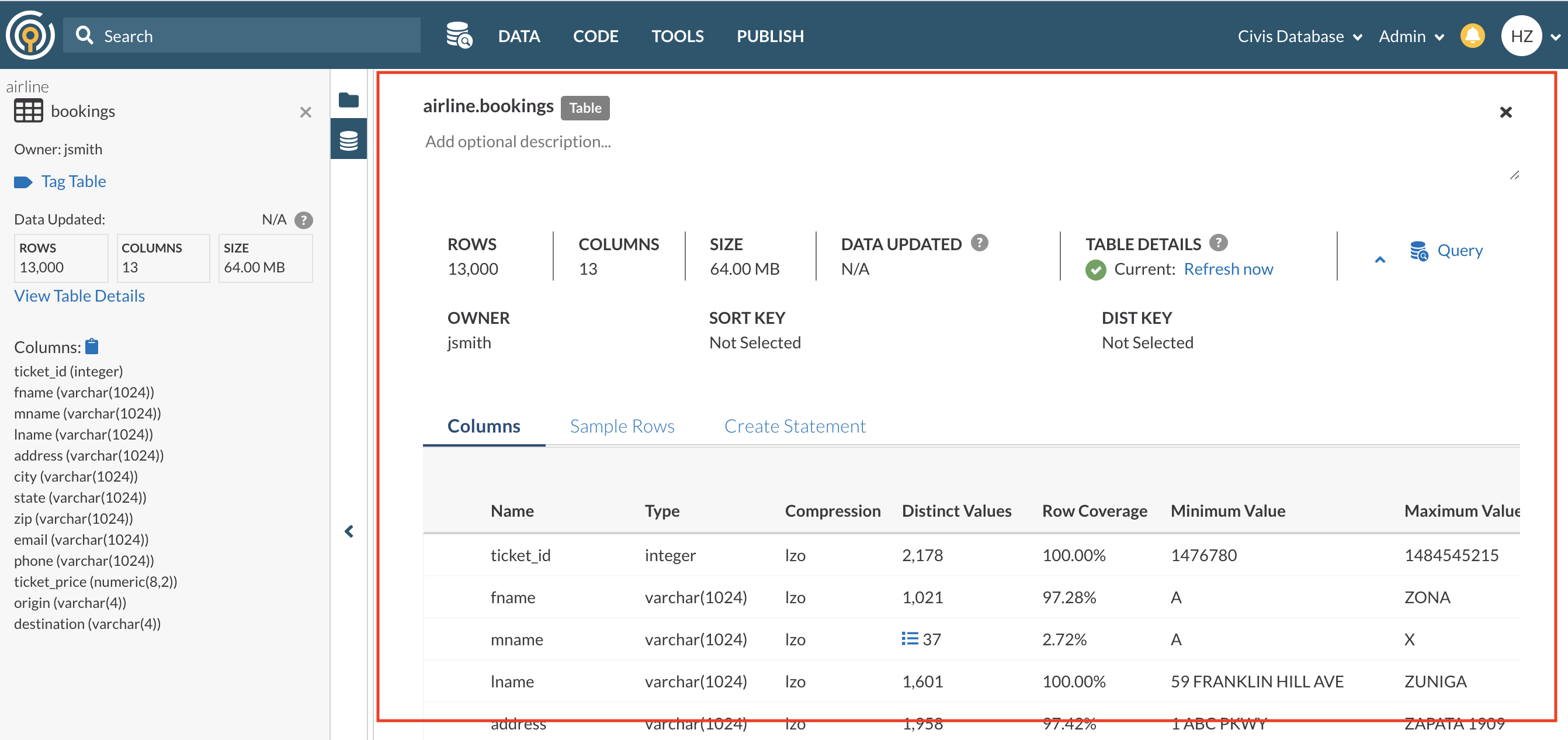
Table Details provide you additional information so that you can better understand, enrich, and trust your dataset. This information includes
- Description - anyone who can see the table can add the description to the table. If this information is available, it will be displayed in Table Snapshot as well.
- Owner
- Any Tags the table is associated with for quick context.
- Data Updated timestamp - the most recent time Platform has detected changes to the data or schema. For more details, please go here.
- Number of Rows
- Number of Columns
- Table Size
- Sort Key - a sort key is a designation given to a column that allows Redshift to optimize its query planning process. For more details, please go here.
- Dist Key - a dist key is a way for Redshift to decide which row goes to which node of a cluster. This can be useful when joining datasets together because it lets Redshift know where to locate the queried data quickly. For more details, please go here.
- Columns statistics
- Database-Native statistics - Platform provides basic column details to help you understand the column definition better
- Data Type
- Compression Scheme - you can see Redshift-specific compression for tables. This information is not available for views.
- Column Description - you can add a column description by utilizing a SQL COMMENT command. To learn how to update your column descriptions for Redshift and Postgres tables, please go here.
- Platform-Generated statistics - Platform generates data distribution statistics so that you can get a quick understanding of the data within each column. To generate the statistics, you can click on Refresh Now. For more details, please go here.
- Table Details freshness status - indicates if Table Details information is up to date. You can click on Refresh Now to get the updated info.
- Distinct Values - if your column has fewer than 60 distinct values, you can click on the blue hamburger icon to see a breakdown of data values and their count. NULL values are also treated as one distinct value.
- Row Coverage - this measures the ratio of NULL values in the column. It’s defined as the ratio of (total number of rows - number of rows that have the NULL value) / (total number of rows).
- Minimum Value
- Maximum Value
- Database-Native statistics - Platform provides basic column details to help you understand the column definition better
- Sample Rows - you can see up to 100 rows
- Create Statement
- Shortcut to the Query tool where you can write SQL queries to explore the table in-depth and in real-time
Important: Please note that Table Details is not a live look at the table.
- If you have changed a table's structure but Platform has yet to reflect those changes, you can click Update Table Details in the Data Pane. This updates table names, column names, and column data types. For newly created tables, the table will appear in the data pane after running this job.
- You can also click on Refresh Now in the Table Details if you want to update information about the data in the table, such as the row count, sample raw rows, and column statistics- min, max, etc.
- For more details on how Platform Updates Data Catalog, please here.
The Privileges tab on Table Details allows you to view what privileges users have on a table and its schema. Read more about Database Privileges here.
A note on Table Descriptions
You can describe your tables in 2 ways:
- Via the Table Details page UI
- Via a SQL COMMENT command (see here for more information)
If you describe your tables in the UI, this table description lives in Platform; if you describe your tables via SQL COMMENT, this table description lives in the database. Your UI updates do not overwrite the table description in the database.
Your UI updates always take precedence over your SQL COMMENT updates. This means the Table Details page will always display the table descriptions you added/updated via the UI. If all your table descriptions updates are added/updated via SQL COMMENT and you do not have table descriptions added in the UI, then the Table Details page will default to displaying the table description from the database instead.
Table Tags
Table Tags enable you to organize and label data across schemas. For example, in Table Snapshot you can tag your production or golden tables to guide analysts to important datasets.
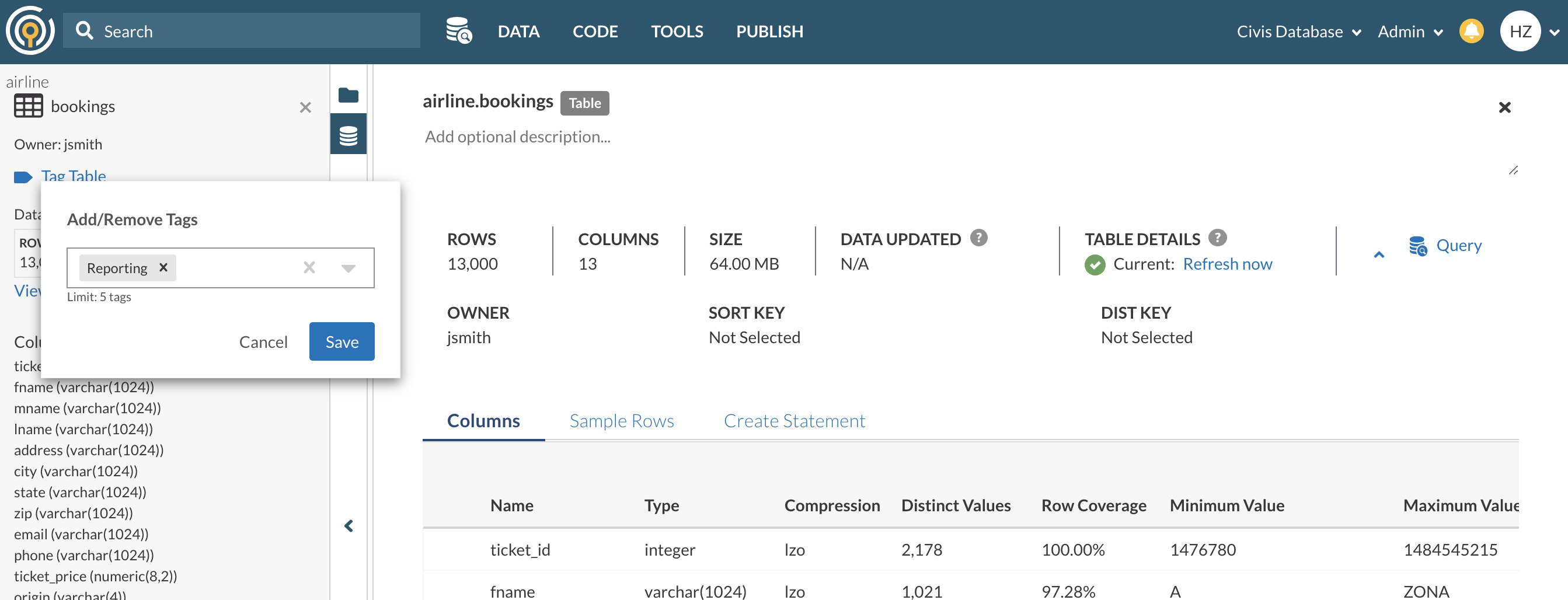
You can also search tables by their associating tags in the Data Pane.
For more details on Table Tags, please go here.
API
All of Platform’s capabilities can be managed via API. You can use the /databases/ endpoints, /tables/ endpoints, and /table_tags/ endpoints to suit your exact needs.
For API docs, please go here.
Table Scanner Keeps Data Catalog Up to Date
Platform is an application that sits on top of a database. In order for Platform to know about the tables and schemas in the database, we run a variety of “table scan” jobs. These jobs are run, either automatically by Platform or manually by a user, to ensure the data presented in Platform is up to date.
There are two types of table scans:
- Summary table scan - updates table attribute information (i.e. table name, column names, and column data types) in both Data Pane and Table Details. For newly created tables, the table will appear in the Data Pane after running this job.
- Deep table scan - updates information about the data in your table, such as the row count, sample rows, and column statistics in Table Snapshot and Table Details. This job is user-initiated only.
Platform-Initiated Table Scan
In order to keep Platform up to date with the tables and views in the underlying database, summary table scan jobs are run automatically by Platform in a variety of places:
- Query and SQL Scripts - Platform detects changes to tables/views and runs summary scans to keep them up to date.
- Imports - Platform runs summary scans when modifying tables/views during the course of the import.
Platform also runs a job called the Database Status regularly in the background to scan any tables or views that were modified outside of the job types listed above. This feature is currently only available on Redshift.
User-Initiated Table Scan
You may want to run a summary or deep table scan job manually if Platform does not know about the table or if Platform does not know that the data is updated.
Summary Table/Schema Scan
You should run a summary table scan job if you know a table exists in the database, but it does not appear in Platform or if a table has been updated in the database, but the changes are not displayed in Platform. You can also run a schema scan if you want to scan all the tables in a schema.
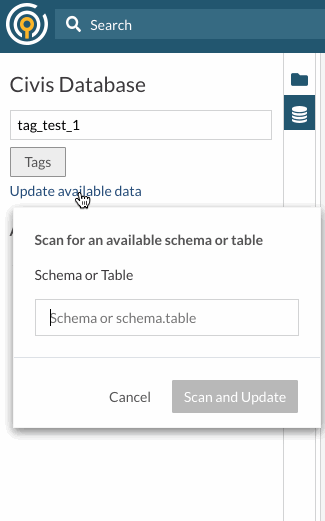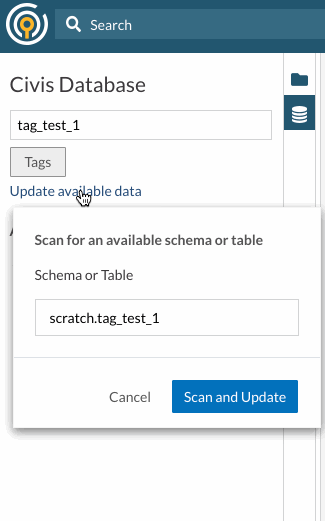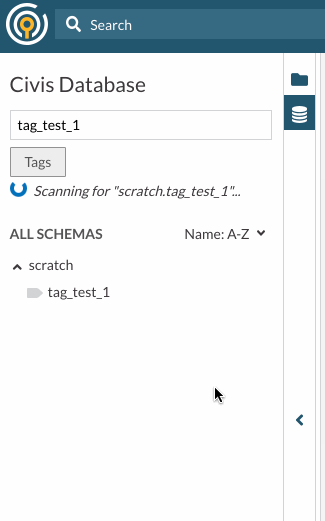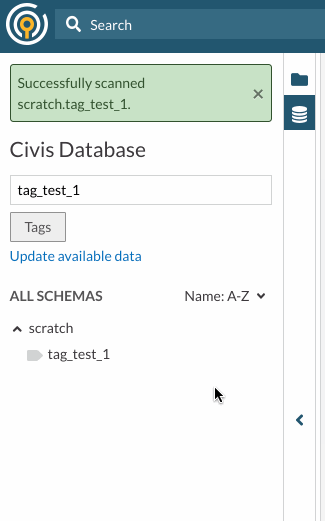
Data Pane > Update Available Data
You can initiate a summary table scan in the Data Pane. To do so
- Click on the link labeled "Update Available Data" under the search bar in the Data Pane.
- Enter either a schema or a table to scan when you are prompted
- Note: be sure to enter your table as schema.table. The schema must be entered for the scan to work.
- Once you enter the schema or table you would like to scan, press enter, or click the "Scan and Update" button to perform a scan. Once the scan is complete, a success or failure notification will pop up.
You can also initiate a summary table scan via the API (use the table/scan endpoint).
Deep Table Scan
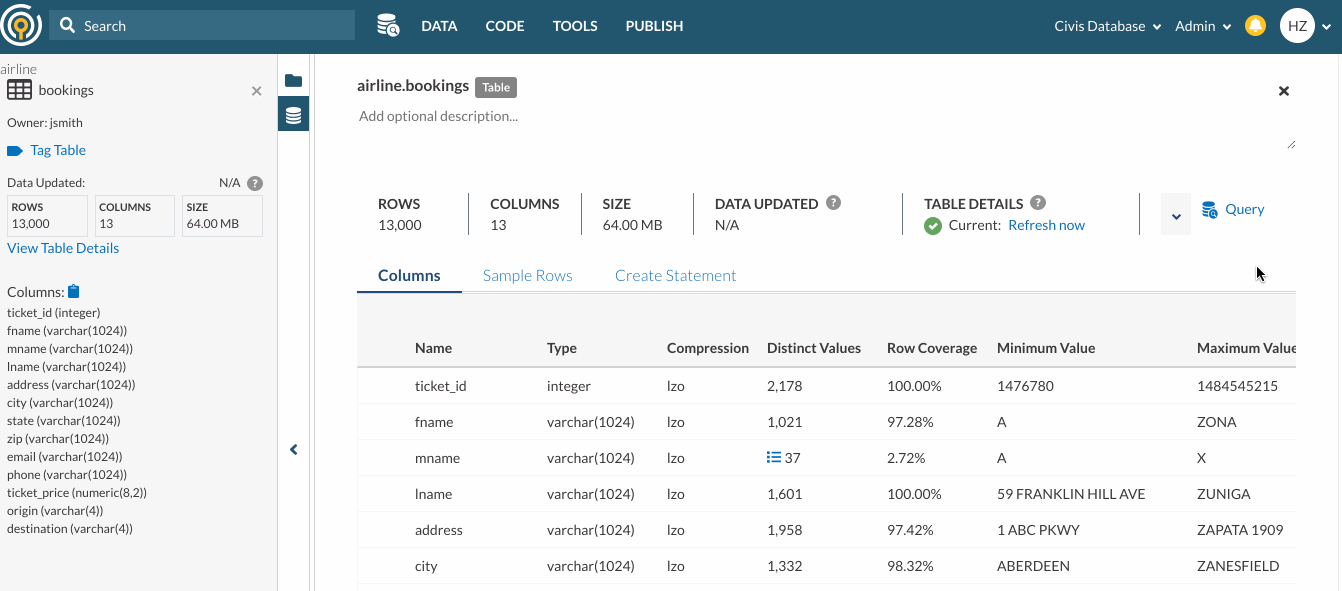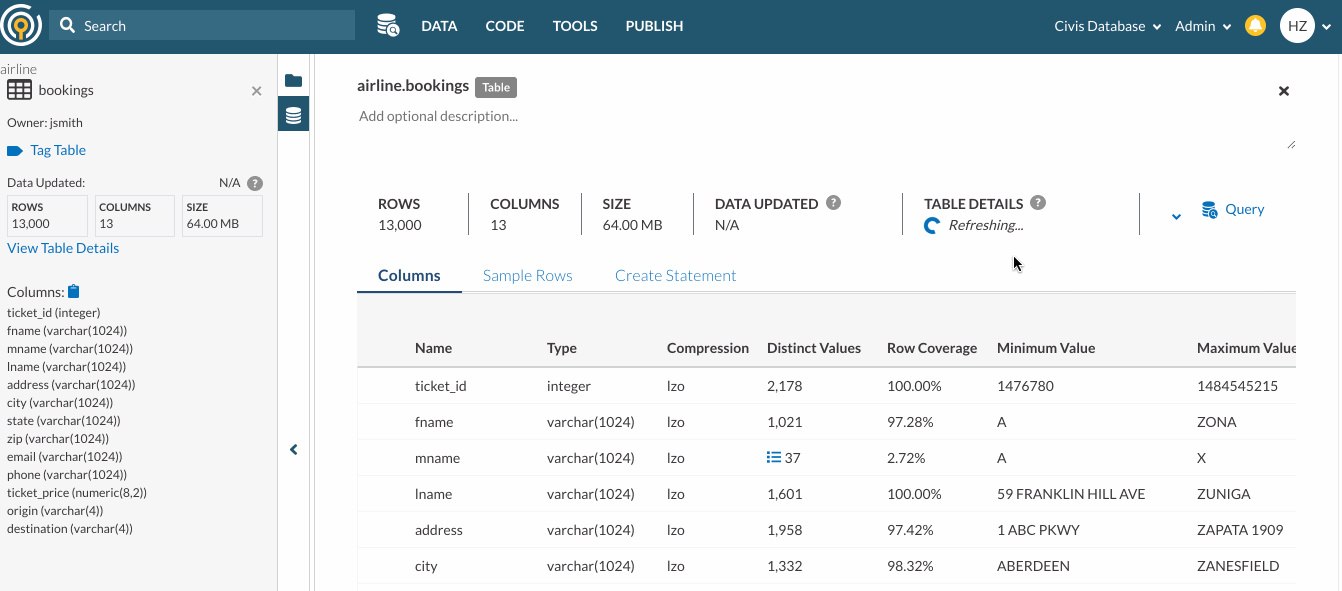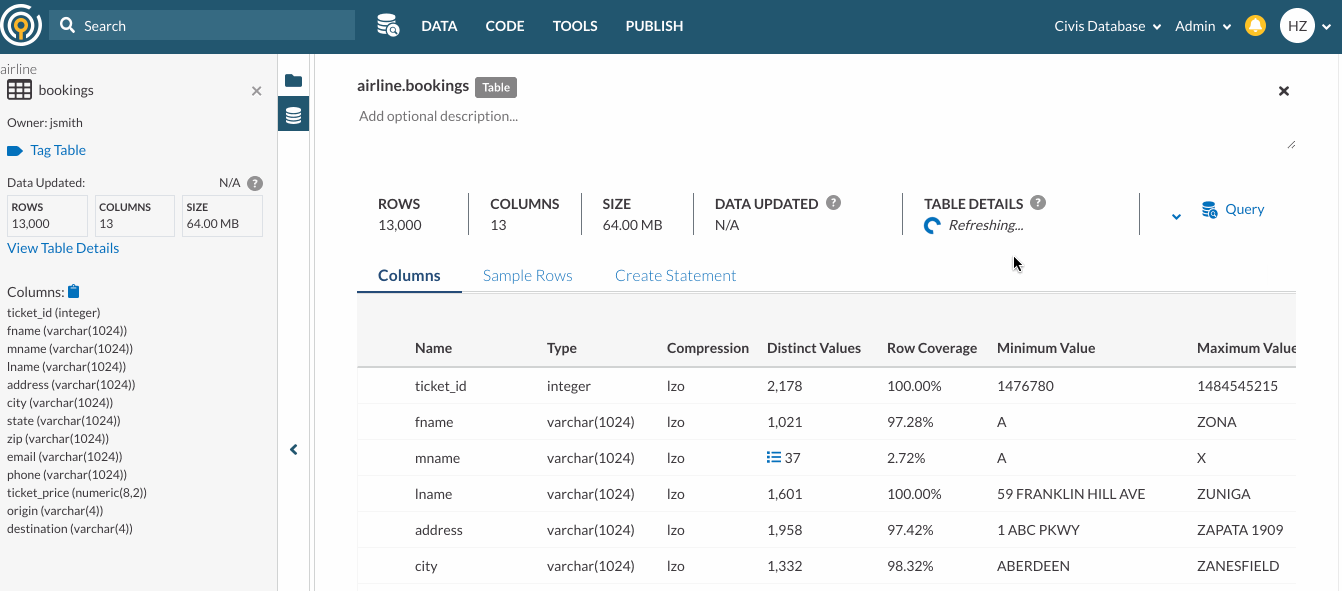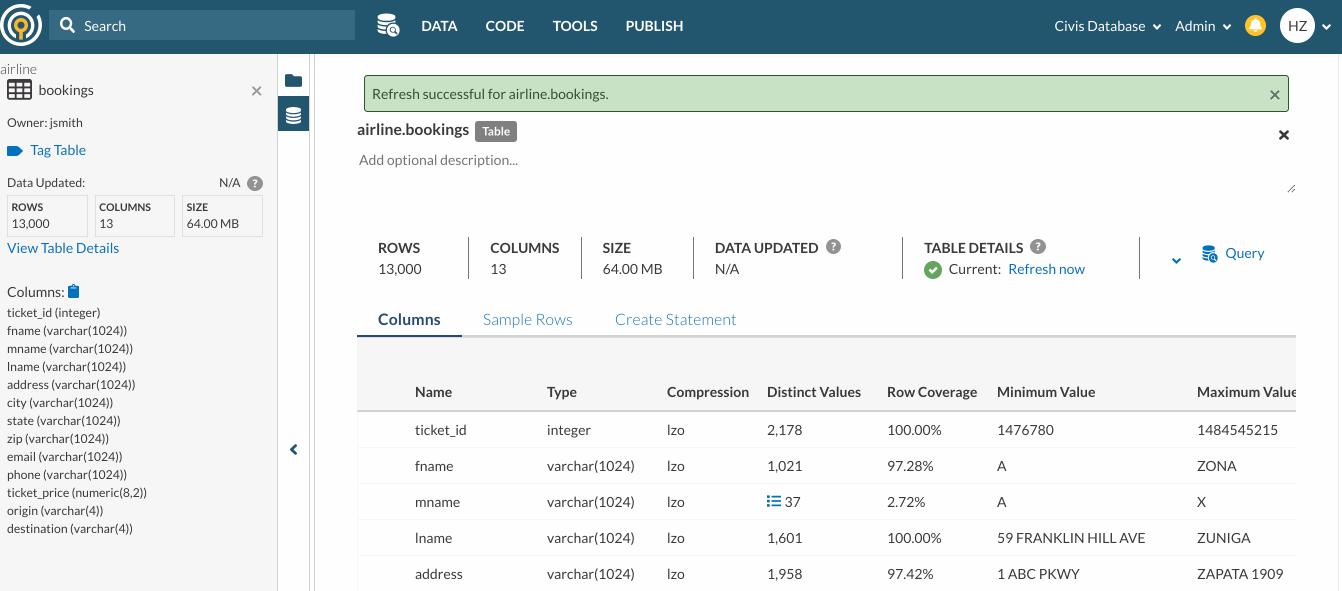
You should run a deep table scan job if you want to update the information about the data in your table, such as the row count, sample rows, and column statistics in Table Snapshot and Table Details. The status on Table Details lets you know whether or not the info is stale and therefore, it’s time for a deep table scan.
Table Details > Refresh Now
You can initiate a deep table scan in Table Details. To do so, click on Refresh Now.
You can also initiate a summary table scan via the API (use the table/scan endpoint and set statsPriority parameter = queue or block).
A Note on the Nightly Cluster Scan
Platform runs a scheduled nightly cluster scan job. This job does a couple of different actions for the entire cluster:
- Checks for any new or updated schemas, tables, or views.
- Updates any stale permissions and tables/schemas Platform does not know about. This ensures that you can see all the tables and schemas you have access to in Platform. This is especially important if you are using a Postgres database since Platform does not have a Database Status job running on Postgres clusters.
Historically, the nightly cluster scan job also ran a deep table scan job on each table. This is no longer the case. Nightly cluster scans also historically ran a VACUUM, which is also no longer the case (Redshift has improved auto-vacuuming, and this also helps prevent cluster slowness due to resource usage).
As the nightly cluster scan jobs are critical for you and your team to be able to see the schemas, tables, and views in the Data Pane, we do not recommend turning these jobs off. If you must turn them off, please contact your client success analyst.
Please note that Redshift UDFs are not supported and therefore we do not recommend using them for making any changes to tables if possible.
Data Updated and Schema Updated
The Data Updated timestamp in the Table Snapshot and Table Details UI indicates the most recent time Platform has detected changes to the schema or to the data for a specific table or view.
Data changes include any time the data has been modified (including dropping and recreating a table) as well as any time a table or view definition has changed. Examples of changes in the table or view definition include (but are not limited to): changing a column name, updating a data type for a column, changing a table name, truncating a table, and inserting data.
Schema changes are changes to the table structure such as someone deleting the table, creating the table, changing the schema name, altering the columns or adding a comment to the table. When a table is dropped or altered, we also update the Data Updated timestamp since this action affects the data of the table.
Unlike in the UI, the Data Updated timestamp in the API indicates the most recent time Platform has detected changes to the data; there’s a separate Schema Updated timestamp field that indicates the most recent time Platform has detected schema changes.
Postgres Databases - The Data Updated timestamp is not supported for Postgres Databases.
How Does Platform Detect Data Changes?
Civis has proprietary software that allows us to identify changes made to tables based on the SQL executed on Redshift. Note: Platform requires users to use a fully qualified table identifier in their SQL in order for it to identify the changes. For example "select * from mytable" will not work but "select * from schema.mytable" will be detected.
For SQL not run directly on Platform (i.e. not Query or SQL Scripts) or obfuscated by non-Platform features, such as stored procedures, Platform may not detect these changes in real-time. Please allow some time for the changes to be detected.
Platform will not be able to detect data changes if you use Redshift UDFs or stored procedures. We do not recommend using these approaches to make any changes to tables if possible.
Comments
0 comments
Please sign in to leave a comment.